

TCP协议
1、TCP协议的特点
传输层中我们常用的协议有两个:TCP协议和UDP协议。TCP协议相对于UDP协议的特点是:面向连接、可靠的、面向字节流的。
使用TCP协议通信的双方在通信之前必须建立连接,然后才能开始进行数据的读写。双方都必须为该连接分配必要的内核资源,以管理连接的状态和连接上数据的传输。TCP连接是全双工的,即一方在向对方发送数据的同时,并不妨碍对方向该方发送数据;数据可以在两个方向上同时传输,而这两个方向的传输是相互独立的,互不干扰。完成数据交换后,通信双方必须断开连接,同时释放连接所占用的网络资源。
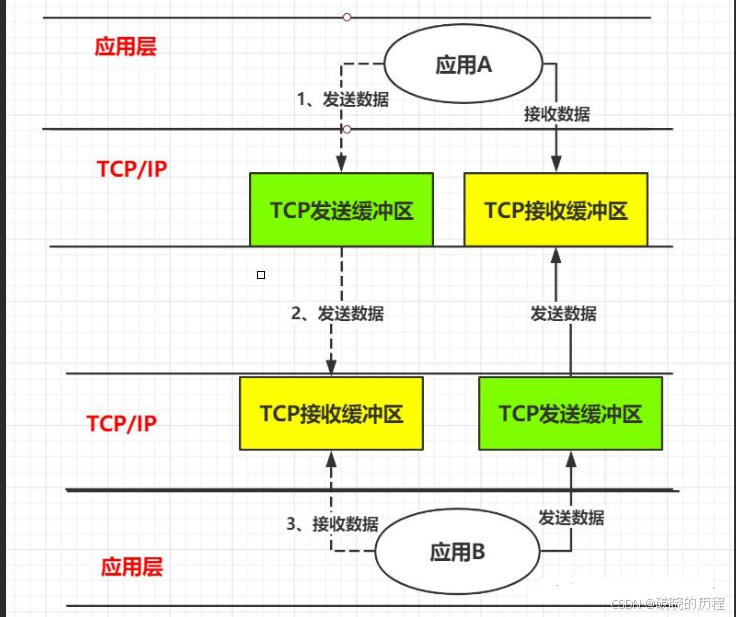
TCP协议属于传输层中的协议,传输层由操作系统管理。在建立连接后,操作系统会为通信双方在内核中创建相应的数据结构和读写缓冲区,通信双方的内核中都有发送缓冲区和接收缓冲区。数据在接收和发送缓冲区内是分离的
那我们在应用层中调用write和read是在干什么呢?
就write函数而言,我们调用write函数就是要告诉操作系统这里有数据要传输,此时的数据就会被拷贝到该端的发送缓冲区中,应用层就返回了。该数据何时发送给对端,数据在传输过程中出现丢包的情况怎么办?这一切由操作系统和TCP协议决定,用户层只是给出建议。所以TCP协议又被称为传输控制协议。
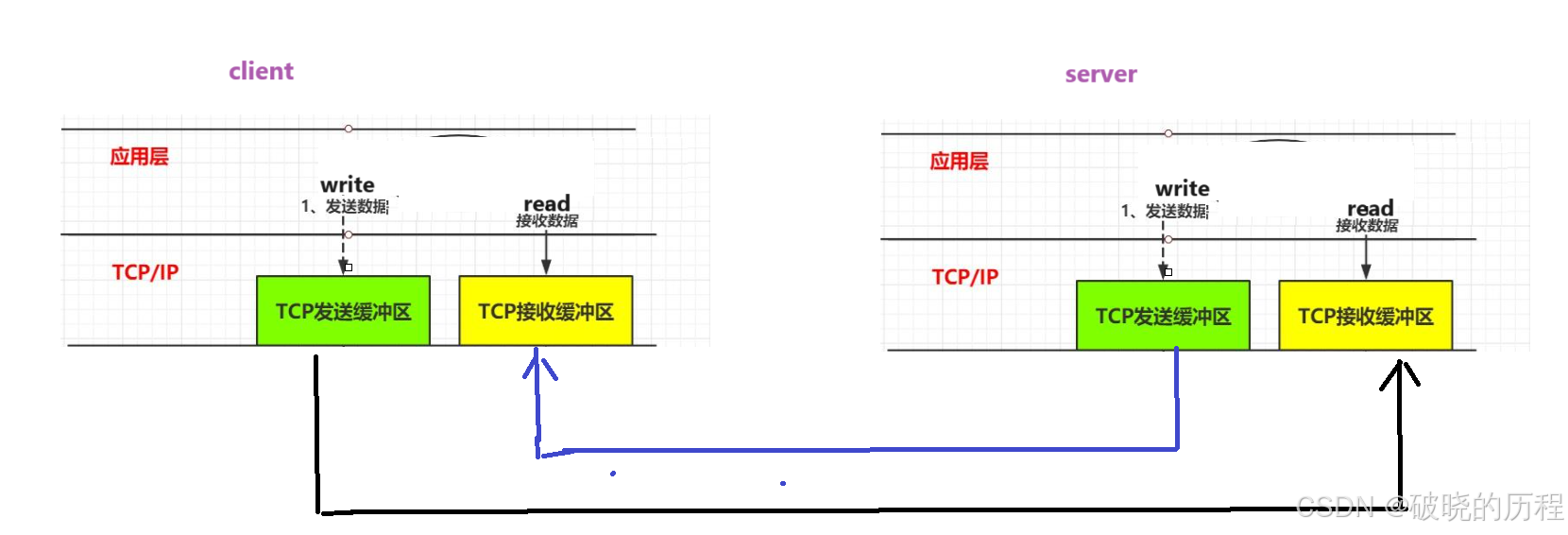
字节流和数据报的区别对应到编码中就是通信双方是否必须执行相同次数的读写操作【这只是表现形式】。
当发送端应用程序连续执行多次写操作时,TCP模块先将这些数据放入TCP发送缓冲区中。当TCP模块真正开始发送数据时,发送缓冲区中这些等待发送的数据可能被封装成一个或者多个TCP报文发出去,因此,TCP模块发送出的TCP报文段的个数和应用程序执行的写操作次数没有固定的数量关系。
当接收缓冲区收到一个或者多个TCP报文后,TCP模块将它们携带的应用程序的数据按照TCP报文的序号【见下文】依次放入TCP接收缓冲区中,并通知应用程序读取数据。接收端应用程序可以一次性的将TCP接收缓冲区内的数据全部读出,也可以分多次读取器,这取决于用户指定的应用程序缓冲区大小。因此,应用程序执行的读操作次数和TCP模块接收到的TCP报文段个数之间没有固定的数量关系。
所以,发送端执行的写操作次数和接收端执行的读操作次数之间没有任何的数量关系,这就是字节流的概念:应用程序对数据的接收和发送是没有边界限制的。UDP则不然,发送端应用程序每执行一次写操作,UDP模块就将其封装成一个UDP数据报并发送之。接收端必须及时针对每一个UDP数据报进行读操作,如果没能及时读取数据报,就有可能发生丢包现象【这经常发生在一些较慢的服务器上】。并且如果用户没有足够的应用程序缓冲区来读取UDP数据,则UDP数据将被截断。
2、确认应答机制
为了使TCP通信更具有可靠性,TCP协议采用了确认应答机制:即发送端发的每一个报文都必须得到对方的应答,才认为这个TCP报文传输成功。其次TCP还采用了超时重传机制,发送端在发送一个TCP报文后启动定时器,如果在约定时间内没有收到对方对该报文的应答信息,发送段将重新发送该报文。并且TCP报文最后是以IP数据报的形式发送的,而IP数据报到达对端可能会出现乱序、重复等情况,所以TCP接收端还要对接收到的报文进行去重、排序等操作,然后再通知应用层读取数据。
3、超时重传机制
对于超过时间限制但未收到应答的报文,TCP协议会重新传输;这也就决定了对已经发送到网络中的数据报的数据,我们不能立即丢弃,应该再保存一段时间,以防报文在传输过程中出现数据丢失的情况。
但是保存在哪里呢?应该保存在TCP维护的发送缓冲区里。
TCP为了保证无论在任何环境下都能比较高性能的通信, 因此会动态计算这个最大超时时间.
- Linux中(BSD Unix和Windows也是如此), 超时以500ms为一个单位进行控制, 每次判定超时重发的超时
- 时间都是500ms的整数倍.
- 如果重发一次之后, 仍然得不到应答, 等待 2*500ms 后再进行重传.
- 如果仍然得不到应答, 等待 4*500ms 进行重传. 依次类推, 以指数形式递增.
- 累计到一定的重传次数, TCP认为网络或者对端主机出现异常, 强制关闭连接